Haeru: Architecture of a Companion That Remembers
Haeru is a life-companion AI. Not a journal with a language model stapled to it. A companion that witnesses your life — pays attention when you aren't, notices what you can't see about yourself, and reaches out when you go quiet.
The north star: "Know your life."
Without its intelligence layer, Haeru is a nice chatbot that forgets you tomorrow. With it, Haeru is the thing that was paying attention when you weren't.
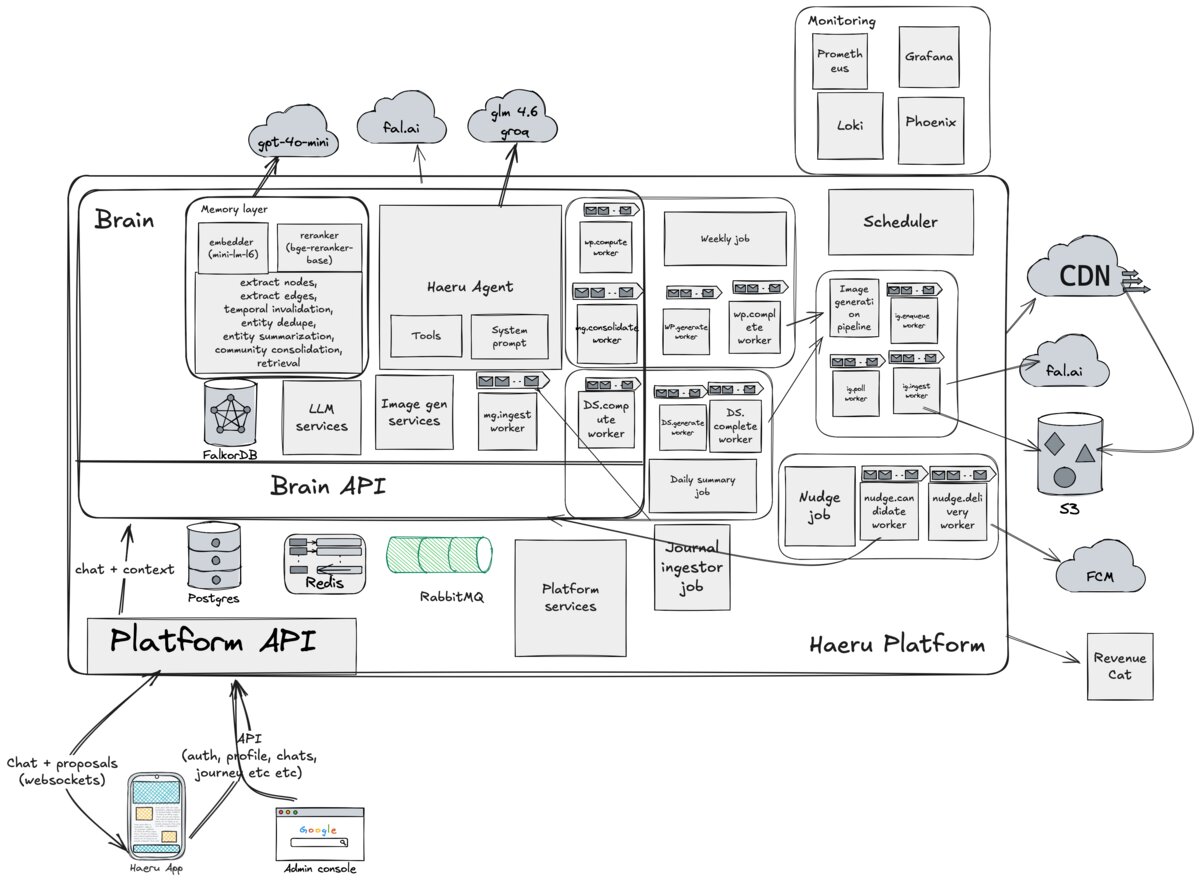
The Topology
Three pillars. Platform is the spine: Gleam on the BEAM VM, HTTP and WebSocket API, 17 OTP-supervised workers, 92 database migrations. Brain is where the thinking happens: Python/FastAPI, chat, memory extraction, knowledge graph, insight engine. iOS is the client: SwiftUI, MVVM, voice mode, the whole native experience.
Why Gleam
Haeru started in Rust.
The compiler errors made AI-assisted coding fast. Type errors were obvious, fixes were mechanical. But build times killed iteration speed. A change-compile-test cycle that should take seconds was taking minutes. When you're a solo founder trying to ship, minutes are not seconds.
Gleam offered the same proposition. Functional, compiled, exhaustive pattern matching, a compiler that catches real bugs, but with instant test runs. The BEAM VM gives you OTP supervision for free, which matters when you're running 17 long-lived RabbitMQ consumers that cannot take down the HTTP listener if one crashes.
They will crash. I learned this the hard way exactly once. An unsupervised consumer crashed, cascaded to its parent, and took down the HTTP listener. Every long-lived process now runs under OTP supervision. OneForOne strategy.
The Intelligence Layer
Three engines, each grounded in specific psychology research:
| Engine | Mode | Core Question |
|---|---|---|
| Grounding | Observing | "Where are you right now?" |
| Insight | Observing | "What can't you see about yourself?" |
| Biographer | Asking | "What don't I know about your life?" |
Research Foundations
Two findings shaped the system's design. The Bias Blind Spot (Pronin, 2007): people reliably detect cognitive biases in others while remaining blind to their own, and intelligence amplifies this. An external observer with memory can see what you cannot. The 43% Problem: 43% of significant life events are systematically omitted from personal narratives. A system that tracks what you've mentioned, and what you haven't, can detect these structural holes.
The delivery principle: "I notice" not "You are." "You have a pattern of avoidance" triggers defensiveness. "I notice you pull back when things get close. What happens there?" opens a door.
The Knowledge Graph: Making an AI Actually Remember
Why a Knowledge Graph
Vanilla RAG — chunk text, embed it, retrieve by similarity — works fine for static documents. It does not work for a life companion. The problem is temporal. People change. You might tell Haeru in January that you're excited about your new job. In March, you're burned out. In June, you quit. A vector database treats these as three similar chunks about "work." A knowledge graph models them as an evolution — the same entity, three states, a trajectory.
Haeru's insight engine needs to say "you were excited about this job five months ago — what changed?" You can't do that with cosine similarity over frozen embeddings. You need structure: nodes that update, relationships that carry timestamps, entities that evolve.
Graphiti and What I Built Around It
Haeru uses Graphiti (built on FalkorDB/Redis) as the foundation. Out of the box, Graphiti handles entity and relationship extraction from text and provides basic hybrid search — semantic similarity plus keyword matching. It's good infrastructure. But a life companion needs more than basic hybrid search.
Everything else is custom work built around Graphiti without forking the library.
Prompt interception. A custom InterceptingOpenAIClient wraps Graphiti's extraction calls to control how entities and relationships are extracted, giving me fine-grained control over what goes into the graph without modifying Graphiti's internals.
PCST for multi-hop retrieval. Standard retrieval fails on multi-hop inference. If a user asks "Why do I always get anxious before visiting my parents?", the answer might require traversing: User → anxiety → childhood home → parents → unresolved argument from six months ago. No single embedding similarity search will find that path. I added the Prize-Collecting Steiner Tree (PCST) algorithm via pcst-fast on top of Graphiti's search results. Given seed nodes from initial search, PCST finds the minimum-cost subgraph that connects them — discovering bridging nodes and relationships that pure similarity search misses completely. Benchmarks confirm it finds answers where reranking alone fails.
The 90x query optimization. Graphiti's default FalkorDB queries used naive pattern matching for edge traversal. The OptimizedFalkorSearchInterface replaces this with startNode()/endNode() calls. 90x speedup.
Reranking layer. ZeroEntropy's zerank-2 model sits on top as an optional reranking pass. The benchmarks: ~636ms additional latency on top of ~1088ms for candidate retrieval, with only 22% overlap with the baseline RRF ranking in top-5 results. The system is selective about when reranking triggers — not every memory lookup needs the expensive path.
Extraction model choice. GPT-4o mini. I tried smaller models first — they were unreliable. When a model hallucinates a relationship that doesn't exist, it poisons the graph. The cost difference wasn't worth the cleanup.
Voice Pipeline
iOS Microphone (16kHz, 80ms chunks)
→ AudioCaptureService → WebSocket → Platform → Deepgram Flux (STT)
→ Brain (FastAPI) → LLM (streaming)
→ SSE stream → Platform → WebSocket → iOS (TTS)Endpoint detection uses a two-phase system:
- Eager threshold (0.6) — start processing, begin thinking about a response
- Final threshold (0.9) — confirm the turn is complete, commit to responding
- TurnResumed — if the user keeps talking after eager detection, cancel in-flight processing
This gives Haeru fast response times: it starts thinking before you're done talking, without getting cut off by a premature response.
Audio is pre-warmed at app launch — the microphone session initializes in the background so there's no cold-start delay when entering voice mode.
The Through Line
The hardest part was never the infrastructure. It was keeping the AI from trying to sound smart when the job is to observe. Different problem entirely.